

 La startup Cerebras publie Cerebras-GPT, une famille de modèles linguistiques de type ChatGPT en open-source, les sept modèles GPT-3 établissent des records de précision et d'efficacité de calcul
La startup Cerebras publie Cerebras-GPT, une famille de modèles linguistiques de type ChatGPT en open-source, les sept modèles GPT-3 établissent des records de précision et d'efficacité de calculLa société Cerebras Systems, spécialisée dans les puces d'intelligence artificielle, a annoncé mardi qu'elle mettait à la disposition des chercheurs et des entreprises des modèles de type ChatGPT en code source libre, afin de favoriser la collaboration.
La société Cerebras, basée dans la Silicon Valley, a publié sept modèles, tous entraînés sur son supercalculateur d'intelligence artificielle Andromeda. Il s'agit de modèles linguistiques de 111 millions de paramètres et d'un modèle plus large de 13 milliards de paramètres.
"Il y a un grand mouvement pour fermer ce qui a été ouvert dans l'IA... ce n'est pas surprenant car il y a maintenant beaucoup d'argent dans ce domaine", a déclaré Andrew Feldman, fondateur et PDG de Cerebras. "L'enthousiasme de la communauté, les progrès que nous avons réalisés, sont dus en grande partie à l'ouverture de la communauté."
Les modèles comportant davantage de paramètres sont capables d'exécuter des fonctions génératives plus complexes.
Le chatbot ChatGPT d'OpenAI, lancé à la fin de l'année dernière, dispose par exemple de 175 milliards de paramètres et peut produire de la poésie et de la recherche, ce qui a contribué à susciter un grand intérêt et un financement important pour l'IA au sens large.
Selon M. Cerebras, les modèles les plus petits peuvent être déployés sur des téléphones ou des haut-parleurs intelligents, tandis que les plus grands fonctionnent sur des PC ou des serveurs, bien que les tâches complexes telles que le résumé de passages importants nécessitent des modèles plus grands.
Cependant, Karl Freund, consultant en puces chez Cambrian AI, a déclaré que ce qui est plus grand n'est pas toujours meilleur.
"Des articles intéressants qui ont été publiés montrent qu'un modèle plus petit peut être précis si vous l'entraînez davantage", a déclaré M. Freund. "Il y a donc un compromis entre un modèle plus grand et un modèle mieux formé."
Selon M. Feldman, l'entraînement de son plus grand modèle a pris un peu plus d'une semaine, un travail qui prend généralement plusieurs mois, grâce à l'architecture du système Cerebras, qui comprend une puce de la taille d'une assiette à dîner conçue pour l'entraînement à l'IA.
La plupart des modèles d'IA sont aujourd'hui formés sur les puces de Nvidia Corp, mais de plus en plus de startups comme Cerebras tentent de prendre des parts de ce marché.
Les modèles formés sur les machines de Cerebras peuvent également être utilisés sur les systèmes Nvidia pour une formation plus poussée ou une personnalisation, a déclaré M. Feldman.
Cerebras-GPT : une famille de grands modèles linguistiques ouverts pour favoriser la collaboration
Résumé
Les modèles de langage de pointe sont extrêmement difficiles à former ; ils nécessitent d'énormes budgets de calcul, des techniques complexes de calcul distribué et une expertise approfondie en ML. Par conséquent, peu d'organisations entraînent de grands modèles de langage (LLM) à partir de zéro. Et de plus en plus, celles qui disposent des ressources et de l'expertise n'ouvrent pas leurs résultats, ce qui marque un changement significatif par rapport à il y a quelques mois.
Chez Cerebras, nous croyons qu'il faut favoriser l'accès libre aux modèles les plus avancés. Dans cette optique, nous sommes fiers d'annoncer la mise à disposition de la communauté open source de Cerebras-GPT, une famille de sept modèles GPT allant de 111 millions à 13 milliards de paramètres. Entraînés en utilisant la formule de Chinchilla, ces modèles offrent la plus grande précision pour un budget de calcul donné. Cerebras-GPT a des temps d'apprentissage plus rapides, des coûts d'apprentissage plus faibles et consomme moins d'énergie que n'importe quel autre modèle disponible à ce jour.
Tous les modèles ont été entraînés sur les systèmes CS-2 qui font partie du supercalculateur Andromeda AI en utilisant notre architecture simple de flux de poids parallèle aux données. Comme nous n'avons pas à nous préoccuper du partitionnement des modèles, nous avons pu entraîner ces modèles en quelques semaines seulement. L'entraînement de ces sept modèles nous a permis de dériver une nouvelle loi d'échelle. Les lois d'échelle prédisent la précision du modèle en fonction du budget de calcul de l'entraînement et ont eu une influence considérable sur l'orientation de la recherche en IA. À notre connaissance, Cerebras-GPT est la première loi d'échelle qui prédit la performance d'un modèle pour un ensemble de données publiques.
La version d'aujourd'hui est conçue pour être utilisée et reproductible par n'importe qui. Tous les modèles, poids et points de contrôle sont disponibles sur Hugging Face et GitHub sous la licence Apache 2.0. En outre, nous fournissons des informations détaillées sur nos méthodes d'entraînement et nos résultats de performance dans notre prochain article. Les systèmes Cerebras CS-2 utilisés pour l'entraînement sont également disponibles à la demande via Cerebras Model Studio.
Cerebras-GPT : Un nouveau modèle pour le développement d'un LLM ouvert
L'intelligence artificielle a le potentiel de transformer l'économie mondiale, mais son accès est de plus en plus limité. Le dernier grand modèle linguistique - le GPT4 d'OpenAI - a été publié sans aucune information sur l'architecture du modèle, les données d'entraînement, le matériel d'entraînement ou les hyperparamètres. Les entreprises construisent de plus en plus de grands modèles en utilisant des ensembles de données fermés et en offrant les résultats du modèle uniquement via un accès API.
Pour que les LLM soient une technologie ouverte et accessible, nous pensons qu'il est important d'avoir accès à des modèles de pointe ouverts, reproductibles et libres de droits pour la recherche et les applications commerciales. À cette fin, nous avons formé une famille de modèles de transformateurs en utilisant les dernières techniques et des ensembles de données ouvertes que nous appelons Cerebras-GPT. Ces modèles constituent la première famille de modèles GPT formés à l'aide de la formule de Chinchilla et publiés sous la licence Apache 2.0.
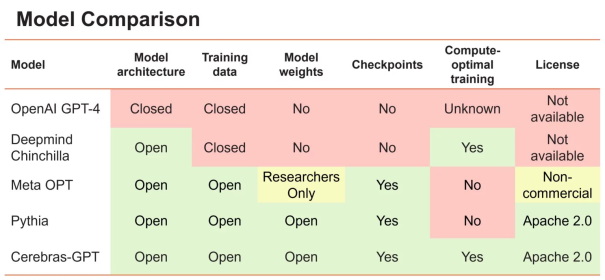
Figure 1. Comparaison de différents grands modèles linguistiques, de leur ouverture et de leur philosophie de formation.
Les grands modèles linguistiques peuvent être classés en deux catégories. Le premier groupe comprend des modèles tels que GPT-4 d'OpenAI et Chinchilla de DeepMind, qui sont entraînés sur des données privées pour atteindre le plus haut niveau de précision. Cependant, les poids entraînés et le code source de ces modèles ne sont pas accessibles au public. Le deuxième groupe comprend des modèles tels que OPT de Meta et Pythia d'Eleuther, qui sont open source mais ne sont pas entraînés de manière optimale pour le calcul.
Par "optimale en termes de calcul", nous faisons référence à la découverte de DeepMind selon laquelle les grands modèles de langage atteignent la plus grande précision pour un budget de calcul fixe lorsque 20 jetons de données sont utilisés pour chaque paramètre du modèle. Par conséquent, un modèle à un milliard de paramètres doit être formé sur 20 milliards de jetons de données pour atteindre des résultats optimaux pour un budget de formation fixe. C'est ce que l'on appelle parfois la "recette Chinchilla".
Cette constatation implique qu'il n'est pas optimal d'utiliser la même quantité de données d'apprentissage lors de l'apprentissage d'une famille de modèles de différentes tailles. Par exemple, l'entraînement d'un petit modèle avec trop de données se traduit par des rendements décroissants et des gains de précision moindres par FLOP - il serait préférable d'utiliser un modèle plus grand avec moins de données. À l'inverse, un grand modèle entraîné avec trop peu de données n'atteint pas son potentiel - il serait préférable de réduire la taille du modèle et de l'alimenter avec plus de données. Dans tous les cas, l'utilisation de 20 jetons par paramètre est optimale, conformément à la recette Chinchilla.

Figure 2. Cerebras-GPT vs. Pythia. Les courbes inférieures indiquent une plus grande efficacité de calcul pour un niveau de perte donné.
La suite de modèles libres Pythia d'EleutherAI est très précieuse pour la communauté des chercheurs car elle fournit un large éventail de tailles de modèles en utilisant l'ensemble de données public Pile dans le cadre d'une méthodologie d'apprentissage contrôlée. Cependant, Pythia a été entraîné avec un nombre fixe de tokens pour toutes les tailles de modèles, dans le but de fournir une base de référence comparable pour tous les modèles.
Conçu pour compléter Pythia, Cerebras-GPT a été conçu pour couvrir une large gamme de tailles de modèles en utilisant le même ensemble de données public Pile et pour établir une loi d'échelle et une famille de modèles efficaces en termes d'entraînement. Cerebras-GPT se compose de sept modèles avec 111 millions, 256 millions, 590 millions, 1,3 milliard, 2,7 milliards, 6,7 milliards et 13 milliards de paramètres, tous entraînés à l'aide de 20 jetons par paramètre. En utilisant les jetons d'entraînement optimaux pour chaque taille de modèle, Cerebras-GPT atteint la perte la plus faible par unité de calcul pour toutes les tailles de modèle (figure 2).
Nouvelle loi de mise à l'échelle
La formation d'un grand modèle linguistique peut être un processus long et coûteux. L'optimisation des performances du modèle nécessite une quantité importante de ressources informatiques et d'expertise. L'un des moyens de relever ce défi consiste à former une famille de modèles de tailles différentes, ce qui permet d'établir une loi d'échelle décrivant la relation entre le calcul de formation et les performances du modèle.

Figure 3. Loi d'échelle Cerebras-GPT
Les lois d'échelle sont essentielles au développement du LLM car elles permettent aux chercheurs de prédire la perte attendue d'un modèle avant l'entraînement, évitant ainsi une recherche coûteuse d'hyperparamètres. OpenAI a été la première à établir une loi d'échelle montrant une relation de type loi de puissance entre le calcul et la perte du modèle. DeepMind a suivi avec l'étude Chinchilla, démontrant un ratio optimal entre le calcul et les données. Toutefois, ces études ont été réalisées à partir d'ensembles de données fermés, ce qui rend difficile l'application des résultats à d'autres ensembles de données.
Cerebras-GPT poursuit cette ligne de recherche en établissant une loi d'échelle basée sur l'ensemble de données ouvert Pile. La loi d'échelle qui en résulte fournit une recette efficace en termes de calcul pour l'entraînement des LLM de toute taille à l'aide de Pile. En publiant nos résultats, nous espérons fournir une ressource précieuse à la communauté et faire progresser le développement de modèles de langage de grande taille.
Performance du modèle sur les tâches en aval
Nous avons évalué les performances de Cerebras-GPT sur plusieurs tâches linguistiques spécifiques telles que l'achèvement de phrases et les questions-réponses. Ces tâches sont importantes car même si les modèles ont une bonne compréhension du langage naturel, cela peut ne pas se traduire par des tâches spécialisées en aval. Nous montrons que Cerebras-GPT conserve une efficacité de formation de pointe pour la plupart des tâches courantes en aval, comme le montrent les exemples de la figure 4. Notamment, alors que les lois de mise à l'échelle précédentes ont montré une mise à l'échelle pour la perte de pré-entraînement, c'est la première fois que des résultats ont été publiés montrant une mise à l'échelle pour les tâches de langage naturel en aval.

Figure 4. Exemple de comparaison des performances de Cerebras-GPT et d'autres modèles open-source pour des tâches en aval. Cerebras-GPT conserve l'avantage de l'efficacité de l'entraînement dans les tâches en aval.
Cerebras CS-2 : Entraînement simple et parallèle aux données
L'entraînement de très grands modèles sur des GPU nécessite une expertise technique considérable. Dans le rapport technique GPT-4 récemment publié, OpenAI mentionne plus de trente contributeurs uniquement pour l'infrastructure de calcul et la mise à l'échelle. Pour comprendre pourquoi, nous allons examiner les techniques de mise à l'échelle LLM existantes sur le GPU, comme le montre la figure 5.
La manière la plus simple de mettre à l'échelle est le parallélisme des données. La mise à l'échelle parallèle aux données réplique le modèle dans chaque dispositif et utilise différents lots d'apprentissage sur ces dispositifs, en faisant la moyenne de leurs gradients. Il est clair que cette méthode ne résout pas le problème de la taille du modèle - elle échoue si le modèle entier ne tient pas sur un seul GPU.
Une approche alternative courante est le modèle parallèle en pipeline, qui exécute différentes couches sur différents GPU en tant que pipeline. Cependant, à mesure que le pipeline s'agrandit, la mémoire d'activation augmente quadratiquement avec la profondeur du pipeline, ce qui peut s'avérer prohibitif pour les modèles de grande taille. Pour éviter cela, une autre approche courante consiste à diviser les couches entre les GPU, appelée modèle tensoriel parallèle, mais cela impose une communication importante entre les GPU, ce qui complique la mise en uvre et peut être lent.
En raison de ces complexités, il n'existe pas aujourd'hui de méthode unique pour faire évoluer les clusters de GPU. L'entraînement de grands modèles sur les GPU nécessite une approche hybride avec toutes les formes de parallélisme ; les implémentations sont compliquées et difficiles à mettre en place, et il y a des problèmes de performance importants.

Figure 5. Techniques existantes de mise à l'échelle sur les grappes de GPU distribuées et leurs difficultés. La mise à l'échelle sur les grappes de GPU nécessite une combinaison complexe de toutes les formes de parallélisme.

Figure 6. La mise à l'échelle des GPU nécessite l'utilisation de plusieurs techniques de parallélisme. Cerebras CS-2 utilise le parallélisme de données pour toutes les tailles de modèles.
Deux grands modèles de langage récents illustrent la complexité de la répartition de grands modèles de langage sur plusieurs GPU (figure 6). Le modèle OPT de Meta, allant de 125 millions à 175 milliards de paramètres, a été entraîné sur 992 GPU en utilisant une combinaison de parallélisme de données et de parallélisme tensoriel ainsi que diverses techniques d'optimisation de la mémoire. Le modèle GPT-NeoX de 20 milliards de paramètres d'Eleuther a utilisé une combinaison de parallélisme de données, de tenseurs et de pipeline pour entraîner le modèle sur 96 GPU.
Cerebras GPT a été entraîné en utilisant un parallélisme de données standard sur 16 systèmes CS-2. Ceci est possible parce que les systèmes Cerebras CS-2 sont équipés de suffisamment de mémoire pour exécuter même les plus grands modèles sur un seul dispositif sans diviser le modèle. Nous avons ensuite conçu le cluster Cerebras Wafer-Scale autour du CS-2 pour faciliter la mise à l'échelle. Il utilise une exécution co-conçue HW/SW appelée weight streaming qui permet une mise à l'échelle indépendante de la taille du modèle et de la taille du cluster, sans parallélisme de modèle. Avec cette architecture, le passage à des grappes plus grandes est aussi simple que de changer le nombre de systèmes dans un fichier de configuration, comme le montre la figure 7.

Figure 7. Mise à l'échelle par bouton-poussoir de plusieurs systèmes CS-2 dans le cluster Cerebras Wafer-Scale en utilisant uniquement un simple parallélisme de données.
Nous avons entraîné tous les modèles Cerebras-GPT sur un cluster 16x CS-2 Cerebras Wafer-Scale appelé Andromeda. Ce cluster a permis de réaliser toutes les expériences rapidement, sans l'ingénierie traditionnelle des systèmes distribués et le réglage parallèle des modèles nécessaires sur les clusters GPU. Plus important encore, il a permis à nos chercheurs de se concentrer sur la conception du ML plutôt que sur le système distribué. Nous pensons que la capacité d'entraîner facilement de grands modèles est un facteur clé pour la communauté élargie, c'est pourquoi nous avons rendu le cluster Cerebras Wafer-Scale disponible sur le cloud à travers le Cerebras AI Model Studio.
Conclusion
Chez Cerebras, nous pensons que la démocratisation des grands modèles nécessite à la fois de résoudre le problème de l'infrastructure d'entraînement et d'ouvrir plus de modèles à la communauté. À cette fin, nous avons conçu le Cerebras Wafer-Scale Cluster avec une mise à l'échelle par bouton-poussoir, et nous mettons en open-sourcing la famille Cerebras-GPT de grands modèles génératifs. Nous espérons qu'en tant que première suite publique de grands modèles GPT avec une efficacité de formation de pointe, Cerebras-GPT servira de recette pour une formation efficace et de référence pour les recherches ultérieures de la communauté. De plus, nous rendons l'infrastructure et les modèles disponibles sur le cloud via le Cerebras AI Model Studio. Nous pensons que c'est grâce à une meilleure infrastructure de formation et à un plus grand partage communautaire que nous pourrons, ensemble, faire progresser l'industrie de l'IA générative.
Auteurs
Nolan Dey, chercheur, Joel Hestness, chercheur principal, Sean Lie, architecte matériel en chef et cofondateur.
Les modèles de langage de pointe sont extrêmement difficiles à former ; ils nécessitent d'énormes budgets de calcul, des techniques complexes de calcul distribué et une expertise approfondie en ML. Par conséquent, peu d'organisations entraînent de grands modèles de langage (LLM) à partir de zéro. Et de plus en plus, celles qui disposent des ressources et de l'expertise n'ouvrent pas leurs résultats, ce qui marque un changement significatif par rapport à il y a quelques mois.
Chez Cerebras, nous croyons qu'il faut favoriser l'accès libre aux modèles les plus avancés. Dans cette optique, nous sommes fiers d'annoncer la mise à disposition de la communauté open source de Cerebras-GPT, une famille de sept modèles GPT allant de 111 millions à 13 milliards de paramètres. Entraînés en utilisant la formule de Chinchilla, ces modèles offrent la plus grande précision pour un budget de calcul donné. Cerebras-GPT a des temps d'apprentissage plus rapides, des coûts d'apprentissage plus faibles et consomme moins d'énergie que n'importe quel autre modèle disponible à ce jour.
Tous les modèles ont été entraînés sur les systèmes CS-2 qui font partie du supercalculateur Andromeda AI en utilisant notre architecture simple de flux de poids parallèle aux données. Comme nous n'avons pas à nous préoccuper du partitionnement des modèles, nous avons pu entraîner ces modèles en quelques semaines seulement. L'entraînement de ces sept modèles nous a permis de dériver une nouvelle loi d'échelle. Les lois d'échelle prédisent la précision du modèle en fonction du budget de calcul de l'entraînement et ont eu une influence considérable sur l'orientation de la recherche en IA. À notre connaissance, Cerebras-GPT est la première loi d'échelle qui prédit la performance d'un modèle pour un ensemble de données publiques.
La version d'aujourd'hui est conçue pour être utilisée et reproductible par n'importe qui. Tous les modèles, poids et points de contrôle sont disponibles sur Hugging Face et GitHub sous la licence Apache 2.0. En outre, nous fournissons des informations détaillées sur nos méthodes d'entraînement et nos résultats de performance dans notre prochain article. Les systèmes Cerebras CS-2 utilisés pour l'entraînement sont également disponibles à la demande via Cerebras Model Studio.
Cerebras-GPT : Un nouveau modèle pour le développement d'un LLM ouvert
L'intelligence artificielle a le potentiel de transformer l'économie mondiale, mais son accès est de plus en plus limité. Le dernier grand modèle linguistique - le GPT4 d'OpenAI - a été publié sans aucune information sur l'architecture du modèle, les données d'entraînement, le matériel d'entraînement ou les hyperparamètres. Les entreprises construisent de plus en plus de grands modèles en utilisant des ensembles de données fermés et en offrant les résultats du modèle uniquement via un accès API.
Pour que les LLM soient une technologie ouverte et accessible, nous pensons qu'il est important d'avoir accès à des modèles de pointe ouverts, reproductibles et libres de droits pour la recherche et les applications commerciales. À cette fin, nous avons formé une famille de modèles de transformateurs en utilisant les dernières techniques et des ensembles de données ouvertes que nous appelons Cerebras-GPT. Ces modèles constituent la première famille de modèles GPT formés à l'aide de la formule de Chinchilla et publiés sous la licence Apache 2.0.
Figure 1. Comparaison de différents grands modèles linguistiques, de leur ouverture et de leur philosophie de formation.
Les grands modèles linguistiques peuvent être classés en deux catégories. Le premier groupe comprend des modèles tels que GPT-4 d'OpenAI et Chinchilla de DeepMind, qui sont entraînés sur des données privées pour atteindre le plus haut niveau de précision. Cependant, les poids entraînés et le code source de ces modèles ne sont pas accessibles au public. Le deuxième groupe comprend des modèles tels que OPT de Meta et Pythia d'Eleuther, qui sont open source mais ne sont pas entraînés de manière optimale pour le calcul.
Par "optimale en termes de calcul", nous faisons référence à la découverte de DeepMind selon laquelle les grands modèles de langage atteignent la plus grande précision pour un budget de calcul fixe lorsque 20 jetons de données sont utilisés pour chaque paramètre du modèle. Par conséquent, un modèle à un milliard de paramètres doit être formé sur 20 milliards de jetons de données pour atteindre des résultats optimaux pour un budget de formation fixe. C'est ce que l'on appelle parfois la "recette Chinchilla".
Cette constatation implique qu'il n'est pas optimal d'utiliser la même quantité de données d'apprentissage lors de l'apprentissage d'une famille de modèles de différentes tailles. Par exemple, l'entraînement d'un petit modèle avec trop de données se traduit par des rendements décroissants et des gains de précision moindres par FLOP - il serait préférable d'utiliser un modèle plus grand avec moins de données. À l'inverse, un grand modèle entraîné avec trop peu de données n'atteint pas son potentiel - il serait préférable de réduire la taille du modèle et de l'alimenter avec plus de données. Dans tous les cas, l'utilisation de 20 jetons par paramètre est optimale, conformément à la recette Chinchilla.
Figure 2. Cerebras-GPT vs. Pythia. Les courbes inférieures indiquent une plus grande efficacité de calcul pour un niveau de perte donné.
La suite de modèles libres Pythia d'EleutherAI est très précieuse pour la communauté des chercheurs car elle fournit un large éventail de tailles de modèles en utilisant l'ensemble de données public Pile dans le cadre d'une méthodologie d'apprentissage contrôlée. Cependant, Pythia a été entraîné avec un nombre fixe de tokens pour toutes les tailles de modèles, dans le but de fournir une base de référence comparable pour tous les modèles.
Conçu pour compléter Pythia, Cerebras-GPT a été conçu pour couvrir une large gamme de tailles de modèles en utilisant le même ensemble de données public Pile et pour établir une loi d'échelle et une famille de modèles efficaces en termes d'entraînement. Cerebras-GPT se compose de sept modèles avec 111 millions, 256 millions, 590 millions, 1,3 milliard, 2,7 milliards, 6,7 milliards et 13 milliards de paramètres, tous entraînés à l'aide de 20 jetons par paramètre. En utilisant les jetons d'entraînement optimaux pour chaque taille de modèle, Cerebras-GPT atteint la perte la plus faible par unité de calcul pour toutes les tailles de modèle (figure 2).
Nouvelle loi de mise à l'échelle
La formation d'un grand modèle linguistique peut être un processus long et coûteux. L'optimisation des performances du modèle nécessite une quantité importante de ressources informatiques et d'expertise. L'un des moyens de relever ce défi consiste à former une famille de modèles de tailles différentes, ce qui permet d'établir une loi d'échelle décrivant la relation entre le calcul de formation et les performances du modèle.
Figure 3. Loi d'échelle Cerebras-GPT
Les lois d'échelle sont essentielles au développement du LLM car elles permettent aux chercheurs de prédire la perte attendue d'un modèle avant l'entraînement, évitant ainsi une recherche coûteuse d'hyperparamètres. OpenAI a été la première à établir une loi d'échelle montrant une relation de type loi de puissance entre le calcul et la perte du modèle. DeepMind a suivi avec l'étude Chinchilla, démontrant un ratio optimal entre le calcul et les données. Toutefois, ces études ont été réalisées à partir d'ensembles de données fermés, ce qui rend difficile l'application des résultats à d'autres ensembles de données.
Cerebras-GPT poursuit cette ligne de recherche en établissant une loi d'échelle basée sur l'ensemble de données ouvert Pile. La loi d'échelle qui en résulte fournit une recette efficace en termes de calcul pour l'entraînement des LLM de toute taille à l'aide de Pile. En publiant nos résultats, nous espérons fournir une ressource précieuse à la communauté et faire progresser le développement de modèles de langage de grande taille.
Performance du modèle sur les tâches en aval
Nous avons évalué les performances de Cerebras-GPT sur plusieurs tâches linguistiques spécifiques telles que l'achèvement de phrases et les questions-réponses. Ces tâches sont importantes car même si les modèles ont une bonne compréhension du langage naturel, cela peut ne pas se traduire par des tâches spécialisées en aval. Nous montrons que Cerebras-GPT conserve une efficacité de formation de pointe pour la plupart des tâches courantes en aval, comme le montrent les exemples de la figure 4. Notamment, alors que les lois de mise à l'échelle précédentes ont montré une mise à l'échelle pour la perte de pré-entraînement, c'est la première fois que des résultats ont été publiés montrant une mise à l'échelle pour les tâches de langage naturel en aval.
Figure 4. Exemple de comparaison des performances de Cerebras-GPT et d'autres modèles open-source pour des tâches en aval. Cerebras-GPT conserve l'avantage de l'efficacité de l'entraînement dans les tâches en aval.
Cerebras CS-2 : Entraînement simple et parallèle aux données
L'entraînement de très grands modèles sur des GPU nécessite une expertise technique considérable. Dans le rapport technique GPT-4 récemment publié, OpenAI mentionne plus de trente contributeurs uniquement pour l'infrastructure de calcul et la mise à l'échelle. Pour comprendre pourquoi, nous allons examiner les techniques de mise à l'échelle LLM existantes sur le GPU, comme le montre la figure 5.
La manière la plus simple de mettre à l'échelle est le parallélisme des données. La mise à l'échelle parallèle aux données réplique le modèle dans chaque dispositif et utilise différents lots d'apprentissage sur ces dispositifs, en faisant la moyenne de leurs gradients. Il est clair que cette méthode ne résout pas le problème de la taille du modèle - elle échoue si le modèle entier ne tient pas sur un seul GPU.
Une approche alternative courante est le modèle parallèle en pipeline, qui exécute différentes couches sur différents GPU en tant que pipeline. Cependant, à mesure que le pipeline s'agrandit, la mémoire d'activation augmente quadratiquement avec la profondeur du pipeline, ce qui peut s'avérer prohibitif pour les modèles de grande taille. Pour éviter cela, une autre approche courante consiste à diviser les couches entre les GPU, appelée modèle tensoriel parallèle, mais cela impose une communication importante entre les GPU, ce qui complique la mise en uvre et peut être lent.
En raison de ces complexités, il n'existe pas aujourd'hui de méthode unique pour faire évoluer les clusters de GPU. L'entraînement de grands modèles sur les GPU nécessite une approche hybride avec toutes les formes de parallélisme ; les implémentations sont compliquées et difficiles à mettre en place, et il y a des problèmes de performance importants.
Figure 5. Techniques existantes de mise à l'échelle sur les grappes de GPU distribuées et leurs difficultés. La mise à l'échelle sur les grappes de GPU nécessite une combinaison complexe de toutes les formes de parallélisme.
Figure 6. La mise à l'échelle des GPU nécessite l'utilisation de plusieurs techniques de parallélisme. Cerebras CS-2 utilise le parallélisme de données pour toutes les tailles de modèles.
Deux grands modèles de langage récents illustrent la complexité de la répartition de grands modèles de langage sur plusieurs GPU (figure 6). Le modèle OPT de Meta, allant de 125 millions à 175 milliards de paramètres, a été entraîné sur 992 GPU en utilisant une combinaison de parallélisme de données et de parallélisme tensoriel ainsi que diverses techniques d'optimisation de la mémoire. Le modèle GPT-NeoX de 20 milliards de paramètres d'Eleuther a utilisé une combinaison de parallélisme de données, de tenseurs et de pipeline pour entraîner le modèle sur 96 GPU.
Cerebras GPT a été entraîné en utilisant un parallélisme de données standard sur 16 systèmes CS-2. Ceci est possible parce que les systèmes Cerebras CS-2 sont équipés de suffisamment de mémoire pour exécuter même les plus grands modèles sur un seul dispositif sans diviser le modèle. Nous avons ensuite conçu le cluster Cerebras Wafer-Scale autour du CS-2 pour faciliter la mise à l'échelle. Il utilise une exécution co-conçue HW/SW appelée weight streaming qui permet une mise à l'échelle indépendante de la taille du modèle et de la taille du cluster, sans parallélisme de modèle. Avec cette architecture, le passage à des grappes plus grandes est aussi simple que de changer le nombre de systèmes dans un fichier de configuration, comme le montre la figure 7.
Figure 7. Mise à l'échelle par bouton-poussoir de plusieurs systèmes CS-2 dans le cluster Cerebras Wafer-Scale en utilisant uniquement un simple parallélisme de données.
Nous avons entraîné tous les modèles Cerebras-GPT sur un cluster 16x CS-2 Cerebras Wafer-Scale appelé Andromeda. Ce cluster a permis de réaliser toutes les expériences rapidement, sans l'ingénierie traditionnelle des systèmes distribués et le réglage parallèle des modèles nécessaires sur les clusters GPU. Plus important encore, il a permis à nos chercheurs de se concentrer sur la conception du ML plutôt que sur le système distribué. Nous pensons que la capacité d'entraîner facilement de grands modèles est un facteur clé pour la communauté élargie, c'est pourquoi nous avons rendu le cluster Cerebras Wafer-Scale disponible sur le cloud à travers le Cerebras AI Model Studio.
Conclusion
Chez Cerebras, nous pensons que la démocratisation des grands modèles nécessite à la fois de résoudre le problème de l'infrastructure d'entraînement et d'ouvrir plus de modèles à la communauté. À cette fin, nous avons conçu le Cerebras Wafer-Scale Cluster avec une mise à l'échelle par bouton-poussoir, et nous mettons en open-sourcing la famille Cerebras-GPT de grands modèles génératifs. Nous espérons qu'en tant que première suite publique de grands modèles GPT avec une efficacité de formation de pointe, Cerebras-GPT servira de recette pour une formation efficace et de référence pour les recherches ultérieures de la communauté. De plus, nous rendons l'infrastructure et les modèles disponibles sur le cloud via le Cerebras AI Model Studio. Nous pensons que c'est grâce à une meilleure infrastructure de formation et à un plus grand partage communautaire que nous pourrons, ensemble, faire progresser l'industrie de l'IA générative.
Auteurs
Nolan Dey, chercheur, Joel Hestness, chercheur principal, Sean Lie, architecte matériel en chef et cofondateur.
Et vous ?
 Quel est votre avis sur le sujet ? Selon vous, les grands modèles linguistiques "open source" peuvent-ils rivaliser avec les modèles propriétaires ? Pensez-vous que cette initiative de Cerebras sera bénéfique pour le domaine de l'IA en général ? Selon vous, la démocratisation des LLM peut-elle redistribuer la donne et réduire l'emprise des géants technologiques sur les outils d'IA générative ?
Quel est votre avis sur le sujet ? Selon vous, les grands modèles linguistiques "open source" peuvent-ils rivaliser avec les modèles propriétaires ? Pensez-vous que cette initiative de Cerebras sera bénéfique pour le domaine de l'IA en général ? Selon vous, la démocratisation des LLM peut-elle redistribuer la donne et réduire l'emprise des géants technologiques sur les outils d'IA générative ?Voir aussi
Cerebras lance une énorme puce de 22 cm pour l'entraînement de réseaux neuronaux, 400 000 curs avec 18 Go de registres Cerebras dévoile le Wafer Scale Engine Two (WSE-2), une puce de 2,6 mille milliards de transistors et de 850 000 curs optimisés pour l'IA Microsoft présente le grand modèle de langage multimodal Kosmos-1, les chercheurs montrent que le passage des LLM aux MLLM offre de nouvelles capacités Google a formé un modèle de langage qui serait capable de répondre aux questions d'ordre médicales avec une précision de 92,6 %, les médecins eux-mêmes ont obtenu un score de 92,9 % Meta dévoile son propre modèle de langage appelé LLaMA, fonctionnant comme un chatbot d'IA ordinaire, et indique qu'il est plus puissant et moins gourmand en ressources que ses concurrents
Vous avez lu gratuitement 33 053 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

