

 La "distillation pas-à-pas", un nouveau paradigme d'apprentissage pour surpasser les performances des grands LLM, avec moins de données d'entraînement et des modèles d'IA de plus petite taille
La "distillation pas-à-pas", un nouveau paradigme d'apprentissage pour surpasser les performances des grands LLM, avec moins de données d'entraînement et des modèles d'IA de plus petite taille Dans un article intitulé "Distilling Step-by-Step ! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", des chercheurs présentent une nouvelle méthode appelée "distilling step-by-step" (distillation pas à pas) qui permet d'extraire des justifications informatives des grands modèles de langage (LLM) pour former efficacement des modèles plus petits spécifiques à une tâche. Cette approche réduit considérablement la taille du modèle et la quantité de données de formation nécessaires, surpassant ainsi les performances des LLM avec invite few-shot. La recherche offre une solution économe en ressources pour le compromis entre la taille du modèle et les données de formation. L'approche de distillation pas à pas est disponible en avant-première privée sur Vertex AI de Google Cloud Platform pour les utilisateurs désirant la tester.
Les grands modèles de langage (LLM) ont permis un nouveau paradigme d'apprentissage économe en données, dans lequel ils peuvent être utilisés pour résoudre de nouvelles tâches inédites par le biais d'une invite zéro-shot ou few-shot. Cependant, les LLM sont difficiles à déployer pour des applications réelles en raison de leur taille. Par exemple, servir un seul LLM de 175 milliards de paramètres nécessite au moins 350 Go de mémoire GPU à l'aide d'une infrastructure spécialisée, sans parler du fait que les LLM de pointe actuels sont composés de plus de 500 milliards de paramètres. De telles exigences de calcul sont inaccessibles pour de nombreuses équipes de recherche, en particulier pour les applications qui nécessitent une faible latence.
Pour contourner ces difficultés de déploiement, les praticiens choisissent souvent de déployer des modèles spécialisés plus petits. Ces modèles plus petits sont formés à l'aide de l'un des deux paradigmes courants : le réglage fin ou la distillation. Le réglage fin met à jour un modèle plus petit pré-entraîné (par exemple, BERT ou T5) en utilisant des données annotées manuellement en aval. La distillation entraîne les mêmes modèles plus petits avec des étiquettes générées par un LLM plus grand. Malheureusement, pour atteindre des performances comparables à celles des LLM, les méthodes de réglage fin nécessitent des étiquettes générées par l'homme, qui sont coûteuses et fastidieuses à obtenir, tandis que la distillation nécessite de grandes quantités de données non étiquetées, qui peuvent également être difficiles à collecter.
Dans "Distilling Step-by-Step ! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", présenté à ACL2023, nous nous sommes attaqués à ce compromis entre la taille du modèle et le coût de la collecte des données d'entraînement. Nous présentons la distillation pas à pas, un nouveau mécanisme simple qui nous permet d'entraîner de plus petits modèles spécifiques à une tâche avec beaucoup moins de données d'entraînement que ne l'exigent les approches standard de réglage fin ou de distillation, qui surpassent les performances des LLM avec des invites few-shot. Nous démontrons que le mécanisme de distillation pas à pas permet à un modèle T5 à 770M paramètres de surpasser le modèle PaLM 540B à quelques coups en utilisant seulement 80 % des exemples dans un ensemble de données de référence, ce qui démontre une réduction de plus de 700x de la taille du modèle avec beaucoup moins de données d'entraînement requises par les approches standard.

Distillation pas à pas
L'idée principale de la distillation pas à pas est d'extraire des justifications informatives en langage naturel (c'est-à-dire des étapes de raisonnement intermédiaires) des LLM, qui peuvent à leur tour être utilisées pour former de petits modèles d'une manière plus efficace en termes de données. Plus précisément, les raisonnements en langage naturel expliquent les liens entre les questions d'entrée et les résultats correspondants. Par exemple, à la question "La chambre de Jesse mesure 11 pieds de long et 15 pieds de large. Si elle a déjà 16 pieds carrés de moquette, de combien de moquette a-t-elle besoin pour couvrir tout le sol ?", un LLM peut être incité par la technique d'incitation de la chaîne de pensée (CoT) à fournir des justifications intermédiaires, telles que : "Surface = longueur * largeur. La chambre de Jesse a 11 * 15 pieds carrés." Cela explique mieux le lien entre l'entrée et la réponse finale, "(11 * 15 ) - 16". Ces raisonnements peuvent contenir des connaissances pertinentes sur la tâche, telles que "Surface = longueur * largeur", qui peuvent initialement nécessiter de nombreuses données pour l'apprentissage des petits modèles. Nous utilisons ces justifications extraites comme une supervision supplémentaire et plus riche pour former les petits modèles, en plus des étiquettes de tâches standard.
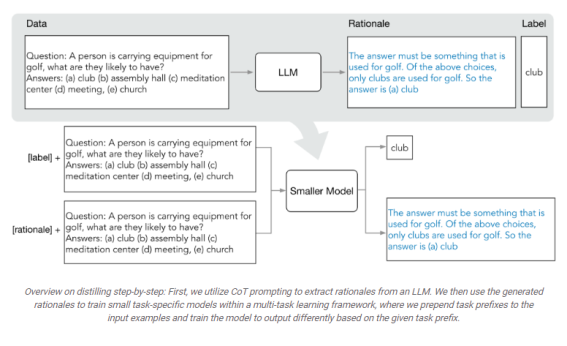
La distillation pas à pas consiste en deux étapes principales. Dans la première étape, nous tirons parti de l'incitation CoT à quelques reprises pour extraire les justifications des LLM. Spécifiquement, étant donné une tâche, nous préparons quelques exemples dans l'invite d'entrée LLM où chaque exemple est composé d'un triplet contenant : (1) entrée, (2) justification, et (3) sortie. Etant donné l'invite, un LLM est capable d'imiter la démonstration du triplet pour générer la justification de toute nouvelle entrée. Par exemple, dans une tâche de réponse à une question de bon sens, étant donné la question d'entrée "Sammy voulait aller là où se trouvent les gens. Où pourrait-il aller ? Choix de réponses : (a) zones peuplées, (b) piste de course, (c) désert, (d) appartement, (e) barrage routier", la distillation pas à pas fournit la réponse correcte à la question, "(a) zones peuplées", associée à la justification qui permet de mieux relier la question à la réponse, "La réponse doit être un endroit où il y a beaucoup de monde. Parmi les choix ci-dessus, seules les zones peuplées ont beaucoup d'habitants". En fournissant des exemples de CoT associés à des justifications dans l'invite, la capacité d'apprentissage en contexte permet aux LLM de produire des justifications correspondantes pour de futurs intrants non vus.

Une fois les justifications extraites, dans la deuxième étape, nous incorporons les justifications dans la formation de petits modèles en définissant le processus de formation comme un problème multitâche. Plus précisément, nous formons le petit modèle avec une nouvelle tâche de génération de justifications en plus de la tâche standard de prédiction d'étiquettes. La tâche de génération de raisonnement permet au modèle d'apprendre à générer les étapes de raisonnement intermédiaires pour la prédiction, et guide le modèle pour mieux prédire l'étiquette résultante. Nous ajoutons des préfixes de tâche (c'est-à-dire [label] et [rationale] pour la prédiction d'étiquette et la génération de justification, respectivement) aux exemples d'entrée du modèle afin de différencier les deux tâches.
Configuration expérimentale
Dans les expériences, nous considérons un modèle PaLM 540B comme LLM. Pour les modèles en aval spécifiques à une tâche, nous utilisons les modèles T5. Pour le prompting CoT, nous utilisons les invites CoT originaux lorsqu'ils sont disponibles et nous sélectionnons nos propres exemples pour les nouveaux ensembles de données. Nous menons les expériences sur quatre ensembles de données de référence dans trois tâches NLP différentes : e-SNLI et ANLI pour l'inférence du langage naturel ; CQA pour la réponse à des questions de bon sens ; et SVAMP pour les problèmes de mots arithmétiques. Nous incluons deux ensembles de méthodes de référence. Pour la comparaison avec les LLM à incitation few-shot, nous comparons le few-shot CoT avec un modèle PaLM 540B. Dans l'article, nous comparons également la formation de modèle standard spécifique à la tâche à la fois au réglage fin standard et à la distillation standard. Dans ce billet de blog, nous nous concentrerons sur les comparaisons avec le réglage fin standard à des fins d'illustration.
Moins de données d'entraînement
Par rapport au réglage fin standard, la méthode de distillation pas à pas permet d'obtenir de meilleures performances en utilisant beaucoup moins de données d'apprentissage. Par exemple, sur l'ensemble de données e-SNLI, nous obtenons de meilleures performances que le réglage fin standard en utilisant seulement 12,5 % de l'ensemble de données complet (illustré dans le quadrant supérieur gauche ci-dessous). De même, nous parvenons à réduire la taille de l'ensemble de données de 75 %, 25 % et 20 % pour ANLI, CQA et SVAMP.

Taille réduite du modèle déployé
Par rapport aux LLM déclenchés par le few-shot CoT, la distillation pas à pas permet d'obtenir de meilleures performances en utilisant des tailles de modèle beaucoup plus petites. Par exemple, sur l'ensemble de données e-SNLI, nous obtenons de meilleures performances que 540B PaLM en utilisant un modèle T5 de 220M. Sur ANLI, nous obtenons de meilleures performances que 540B PaLM en utilisant un modèle T5 de 770M, qui est plus de 700X plus petit. Notez que sur ANLI, le même modèle 770M T5 peine à atteindre les performances de PaLM en utilisant un réglage fin standard.

La distillation pas à pas est plus performante que les LLM à invites few-shot grâce à des modèles plus petits utilisant moins de données
Enfin, nous explorons les plus petites tailles de modèle et la plus petite quantité de données pour que la distillation pas à pas surpasse les performances du PaLM. Par exemple, sur ANLI, nous dépassons les performances du PaLM 540B en utilisant un modèle T5 770M. Ce modèle plus petit n'utilise que 80 % de l'ensemble des données. Parallèlement, nous observons que le réglage fin standard ne peut pas rattraper les performances du PaLM, même en utilisant 100 % de l'ensemble des données. Cela suggère que la distillation pas à pas réduit simultanément la taille du modèle ainsi que la quantité de données nécessaires pour surpasser les LLM.

Conclusion
Nous proposons la distillation pas à pas, un nouveau mécanisme qui extrait les justifications des LLM en tant que supervision informative dans l'apprentissage de petits modèles spécifiques à une tâche. Nous montrons que la distillation pas à pas réduit à la fois l'ensemble de données d'entraînement nécessaire pour créer de petits modèles spécifiques à une tâche et la taille du modèle nécessaire pour atteindre, et même dépasser, la performance d'un LLM à quelques coups. Dans l'ensemble, la distillation pas à pas présente un paradigme efficace en termes de ressources qui permet de trouver un compromis entre la taille du modèle et les données d'entraînement requises.
Disponibilité sur Google Cloud Platform
La distillation pas à pas est disponible en avant-première privée sur Vertex AI. Si vous souhaitez l'essayer, veuillez contacter vertex-llm-tuning-preview@google.com en indiquant votre numéro de projet Google Cloud et un résumé de votre cas d'utilisation.
Remerciements
Cette recherche a été menée par Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee et Tomas Pfister. Merci à Xiang Zhang et Sergey Ioffe pour leurs précieux commentaires.
Pour contourner ces difficultés de déploiement, les praticiens choisissent souvent de déployer des modèles spécialisés plus petits. Ces modèles plus petits sont formés à l'aide de l'un des deux paradigmes courants : le réglage fin ou la distillation. Le réglage fin met à jour un modèle plus petit pré-entraîné (par exemple, BERT ou T5) en utilisant des données annotées manuellement en aval. La distillation entraîne les mêmes modèles plus petits avec des étiquettes générées par un LLM plus grand. Malheureusement, pour atteindre des performances comparables à celles des LLM, les méthodes de réglage fin nécessitent des étiquettes générées par l'homme, qui sont coûteuses et fastidieuses à obtenir, tandis que la distillation nécessite de grandes quantités de données non étiquetées, qui peuvent également être difficiles à collecter.
Dans "Distilling Step-by-Step ! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes", présenté à ACL2023, nous nous sommes attaqués à ce compromis entre la taille du modèle et le coût de la collecte des données d'entraînement. Nous présentons la distillation pas à pas, un nouveau mécanisme simple qui nous permet d'entraîner de plus petits modèles spécifiques à une tâche avec beaucoup moins de données d'entraînement que ne l'exigent les approches standard de réglage fin ou de distillation, qui surpassent les performances des LLM avec des invites few-shot. Nous démontrons que le mécanisme de distillation pas à pas permet à un modèle T5 à 770M paramètres de surpasser le modèle PaLM 540B à quelques coups en utilisant seulement 80 % des exemples dans un ensemble de données de référence, ce qui démontre une réduction de plus de 700x de la taille du modèle avec beaucoup moins de données d'entraînement requises par les approches standard.
Distillation pas à pas
L'idée principale de la distillation pas à pas est d'extraire des justifications informatives en langage naturel (c'est-à-dire des étapes de raisonnement intermédiaires) des LLM, qui peuvent à leur tour être utilisées pour former de petits modèles d'une manière plus efficace en termes de données. Plus précisément, les raisonnements en langage naturel expliquent les liens entre les questions d'entrée et les résultats correspondants. Par exemple, à la question "La chambre de Jesse mesure 11 pieds de long et 15 pieds de large. Si elle a déjà 16 pieds carrés de moquette, de combien de moquette a-t-elle besoin pour couvrir tout le sol ?", un LLM peut être incité par la technique d'incitation de la chaîne de pensée (CoT) à fournir des justifications intermédiaires, telles que : "Surface = longueur * largeur. La chambre de Jesse a 11 * 15 pieds carrés." Cela explique mieux le lien entre l'entrée et la réponse finale, "(11 * 15 ) - 16". Ces raisonnements peuvent contenir des connaissances pertinentes sur la tâche, telles que "Surface = longueur * largeur", qui peuvent initialement nécessiter de nombreuses données pour l'apprentissage des petits modèles. Nous utilisons ces justifications extraites comme une supervision supplémentaire et plus riche pour former les petits modèles, en plus des étiquettes de tâches standard.
La distillation pas à pas consiste en deux étapes principales. Dans la première étape, nous tirons parti de l'incitation CoT à quelques reprises pour extraire les justifications des LLM. Spécifiquement, étant donné une tâche, nous préparons quelques exemples dans l'invite d'entrée LLM où chaque exemple est composé d'un triplet contenant : (1) entrée, (2) justification, et (3) sortie. Etant donné l'invite, un LLM est capable d'imiter la démonstration du triplet pour générer la justification de toute nouvelle entrée. Par exemple, dans une tâche de réponse à une question de bon sens, étant donné la question d'entrée "Sammy voulait aller là où se trouvent les gens. Où pourrait-il aller ? Choix de réponses : (a) zones peuplées, (b) piste de course, (c) désert, (d) appartement, (e) barrage routier", la distillation pas à pas fournit la réponse correcte à la question, "(a) zones peuplées", associée à la justification qui permet de mieux relier la question à la réponse, "La réponse doit être un endroit où il y a beaucoup de monde. Parmi les choix ci-dessus, seules les zones peuplées ont beaucoup d'habitants". En fournissant des exemples de CoT associés à des justifications dans l'invite, la capacité d'apprentissage en contexte permet aux LLM de produire des justifications correspondantes pour de futurs intrants non vus.
Une fois les justifications extraites, dans la deuxième étape, nous incorporons les justifications dans la formation de petits modèles en définissant le processus de formation comme un problème multitâche. Plus précisément, nous formons le petit modèle avec une nouvelle tâche de génération de justifications en plus de la tâche standard de prédiction d'étiquettes. La tâche de génération de raisonnement permet au modèle d'apprendre à générer les étapes de raisonnement intermédiaires pour la prédiction, et guide le modèle pour mieux prédire l'étiquette résultante. Nous ajoutons des préfixes de tâche (c'est-à-dire [label] et [rationale] pour la prédiction d'étiquette et la génération de justification, respectivement) aux exemples d'entrée du modèle afin de différencier les deux tâches.
Configuration expérimentale
Dans les expériences, nous considérons un modèle PaLM 540B comme LLM. Pour les modèles en aval spécifiques à une tâche, nous utilisons les modèles T5. Pour le prompting CoT, nous utilisons les invites CoT originaux lorsqu'ils sont disponibles et nous sélectionnons nos propres exemples pour les nouveaux ensembles de données. Nous menons les expériences sur quatre ensembles de données de référence dans trois tâches NLP différentes : e-SNLI et ANLI pour l'inférence du langage naturel ; CQA pour la réponse à des questions de bon sens ; et SVAMP pour les problèmes de mots arithmétiques. Nous incluons deux ensembles de méthodes de référence. Pour la comparaison avec les LLM à incitation few-shot, nous comparons le few-shot CoT avec un modèle PaLM 540B. Dans l'article, nous comparons également la formation de modèle standard spécifique à la tâche à la fois au réglage fin standard et à la distillation standard. Dans ce billet de blog, nous nous concentrerons sur les comparaisons avec le réglage fin standard à des fins d'illustration.
Moins de données d'entraînement
Par rapport au réglage fin standard, la méthode de distillation pas à pas permet d'obtenir de meilleures performances en utilisant beaucoup moins de données d'apprentissage. Par exemple, sur l'ensemble de données e-SNLI, nous obtenons de meilleures performances que le réglage fin standard en utilisant seulement 12,5 % de l'ensemble de données complet (illustré dans le quadrant supérieur gauche ci-dessous). De même, nous parvenons à réduire la taille de l'ensemble de données de 75 %, 25 % et 20 % pour ANLI, CQA et SVAMP.
Taille réduite du modèle déployé
Par rapport aux LLM déclenchés par le few-shot CoT, la distillation pas à pas permet d'obtenir de meilleures performances en utilisant des tailles de modèle beaucoup plus petites. Par exemple, sur l'ensemble de données e-SNLI, nous obtenons de meilleures performances que 540B PaLM en utilisant un modèle T5 de 220M. Sur ANLI, nous obtenons de meilleures performances que 540B PaLM en utilisant un modèle T5 de 770M, qui est plus de 700X plus petit. Notez que sur ANLI, le même modèle 770M T5 peine à atteindre les performances de PaLM en utilisant un réglage fin standard.
La distillation pas à pas est plus performante que les LLM à invites few-shot grâce à des modèles plus petits utilisant moins de données
Enfin, nous explorons les plus petites tailles de modèle et la plus petite quantité de données pour que la distillation pas à pas surpasse les performances du PaLM. Par exemple, sur ANLI, nous dépassons les performances du PaLM 540B en utilisant un modèle T5 770M. Ce modèle plus petit n'utilise que 80 % de l'ensemble des données. Parallèlement, nous observons que le réglage fin standard ne peut pas rattraper les performances du PaLM, même en utilisant 100 % de l'ensemble des données. Cela suggère que la distillation pas à pas réduit simultanément la taille du modèle ainsi que la quantité de données nécessaires pour surpasser les LLM.
Conclusion
Nous proposons la distillation pas à pas, un nouveau mécanisme qui extrait les justifications des LLM en tant que supervision informative dans l'apprentissage de petits modèles spécifiques à une tâche. Nous montrons que la distillation pas à pas réduit à la fois l'ensemble de données d'entraînement nécessaire pour créer de petits modèles spécifiques à une tâche et la taille du modèle nécessaire pour atteindre, et même dépasser, la performance d'un LLM à quelques coups. Dans l'ensemble, la distillation pas à pas présente un paradigme efficace en termes de ressources qui permet de trouver un compromis entre la taille du modèle et les données d'entraînement requises.
Disponibilité sur Google Cloud Platform
La distillation pas à pas est disponible en avant-première privée sur Vertex AI. Si vous souhaitez l'essayer, veuillez contacter vertex-llm-tuning-preview@google.com en indiquant votre numéro de projet Google Cloud et un résumé de votre cas d'utilisation.
Remerciements
Cette recherche a été menée par Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee et Tomas Pfister. Merci à Xiang Zhang et Sergey Ioffe pour leurs précieux commentaires.
Et vous ?
 Quel est votre avis sur le sujet ? Que pensez-vous de ce nouveau paradigme d'apprentissage des modèles de langage ? Trouvez-vous que c'est un apport bénéfique pour l'IA en général ? Selon vous, l'application de ce nouveau mécanisme d'apprentissage peut-elle conduire à une meilleure adoption de l'IA qu'elle ne l'est aujourd'hui ?
Quel est votre avis sur le sujet ? Que pensez-vous de ce nouveau paradigme d'apprentissage des modèles de langage ? Trouvez-vous que c'est un apport bénéfique pour l'IA en général ? Selon vous, l'application de ce nouveau mécanisme d'apprentissage peut-elle conduire à une meilleure adoption de l'IA qu'elle ne l'est aujourd'hui ?Voir aussi
La startup Cerebras publie Cerebras-GPT, une famille de modèles linguistiques de type ChatGPT en open-source, les sept modèles GPT-3 établissent des records de précision et d'efficacité de calcul Microsoft AI présente Orca : un modèle à 13 milliards de paramètres qui apprend à imiter le processus de raisonnement des grands modèles fondamentaux, ses performances égalent celles de ChatGPT Guidance, un langage pour le contrôle des grands modèles linguistiques modernes, il serait plus efficace et plus efficient que l'invite ou le chaînage traditionnel
Vous avez lu gratuitement 9 520 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.